
Nvidia ha levantado el velo sobre todos los pequeños detalles de la arquitectura Turing, una nueva arquitectura hecha para con vistas al futuro. Turing es un sistema híbrido de generación gráfica, incluyendo componentes que sirven para la renderización por trazado de rayos como la más tradicional rasterización. Todos los detalles públicos de la arquitectura, salvo la salsa secreta a nivel físico, están publicados en el libro blanco de Turing, disponible para cualquiera que le quiera echar un vistazo.
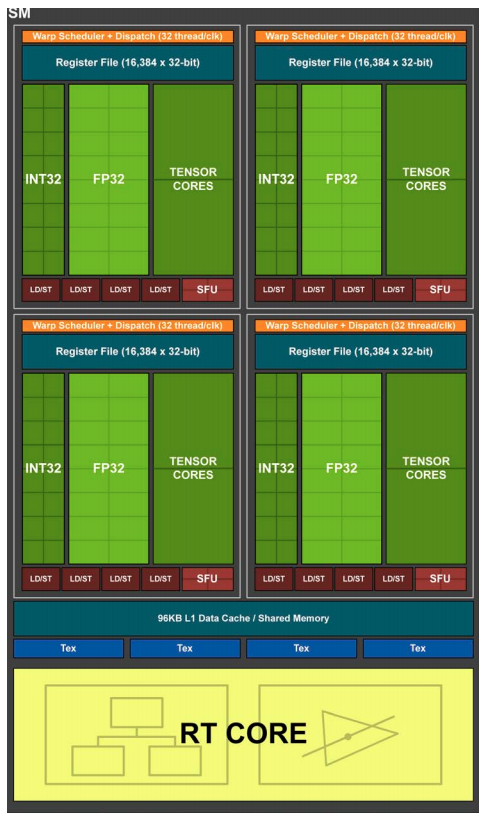
Este sistema híbrido de creación de gráficos está hecho para ser retrocompatible con los juegos actuales, pero asienta la base para un futuro cambio a la generación de gráficos exclusivamente por trazado de rayos. Y para ello, Nvidia ha hecho multitud de cambios a nivel de la unidad mínima de funcionamiento de sus tarjetas gráficas, que es el multiprocesador de flujos de datos o SM.
Como ya había comentado anteriormente, cada SM se compone de 64 núcleos de tipo FP32 y otros 64 núcleos de tipo INT32. Es un desdoblamiento de la funcionalidad de los núcleos CUDA más clásicos, que ejecutaban ambos tipos de operaciones. Pero el desdoblamiento de los núcleos CUDA en dos tipos aumenta, según la compañía, notablemente su rendimiento. Nvidia habla de un rendimiento mejorado de hasta el 50 % en diversos juegos gracias a ello, como por ejemplo Battlefield 1, aunque en otros sea inferior, como un 17 % aproximadamente en The Witcher 3.

Cada SM está dividido en cuatro bloques de procesamiento de dieciséis núcleos FP32 y otros tantos INT32, dos núcleos tensoriales y un gestor de urdimbres, así como una unidad de ejecución. Se incluye como novedad una caché de nivel 0 (L0) de instrucciones, y un registro de 64 KB. Los cuatro bloques comparten los 96 KB de caché de nivel 1 (L1). La caché L2 se duplica hasta llegar a los 6 MB.
La segunda generación de núcleos tensoriales, como ya había mencionado Nvidia anteriormente, añade modos de ejecución en INT4 e INT8 para cargas de trabajo que tengan que ver con las inferencias, que es detectar objetos o patrones en imágenes y que es fundamental en la inteligencia artificial. Es por tanto la base de lo que conforma el supermuestro por inteligencia artificial (DLSS, deep learning super sampling) con el que Nvidia promete llevar el suavizado de bordes fuera de los núcleos CUDA para mejorar su rendimiento.
Cada núcleo tensorial de los 576 que tiene el chip TU102 tiene potencia para ejecutar 64 operaciones de multiplicación-suma por ciclo de reloj utilizando entradas FP16. Aprovechando las nuevas capacidades de ejecución de enteros, puede ejecutar 256 operaciones de enteros por ciclo de reloj, o 2048 por SM.
En cuanto a la memoria, la GPU puede trabajar únicamente con memoria GDDR6, lo cual le dota de un mayor ancho de banda respecto a la GDDR5X usada hasta ahora. Han incluido mejoras para que funcionen las interconexiones más rápidamente, sean más energéticamente eficientes y se reduzca el ruido en la alimentación. Partiendo de 14 Gb/s, es un 20 % más efeciente que la memoria GDDR5X de la arquitectura Pascal.
Nvidia también incide en las mejoras en la compresión de memoria. Es una técnica utilizada para reducir el consumo de ancho de banda en el traslado de información en la tarjeta gráfica, y ahora se usa una compresión sin pérdida que mejora hasta un 50 % el ancho de banda efectivo de la tarjeta gráfica respecto al ancho de banda físico.

En cuanto al motor de vídeo y pantalla, Turing es compatible con DisplayPort 1.4a, con un ancho de banda de 8.1 Gb/s, el mismo que DP1.4, si bien se pasa de ser compatible con vídeo a 5K y 60 Hz a serlo con 8K y 60 Hz. Nvidia despeja cualquier duda que pudiera existir sobre el conector USB tipo C de las GeForce RTX al indicar que son compatible con DisplayPort 1.4a y por tanto se puede usar ese USB tipo C para conectarlo a un monitor con otro USB tipo C de vídeo.
No tiene problemas a la hora de reproducir contenido de alto rango dinámico (HDR), y añade la fórmula del mapa de tonos de la recomendación BT.2100 de la ITU-R para evitar cambios de color en distintas pantallas HDR. Incluye también una unidad codificadora mejorada compatible con HEVC a 8K y 30 FPS, ahorrando un 25 % de ancho de banda y hasta un 15 % en H.264. También es compatible con HEVC YUV444 de 10 y 12 bits a 30 FPS, H.264 a 8K y V9 a 10 y 12 bits con HDR.
El conector USB tipo C es sobre todo para conectar dispositivos que hagan uso del estándar de realidad virtual VirtualLink en el que se están centrando todas las empresas del sector. A través de un solo cable USB tipo C se retransmite vídeo con cuatro canales DisplayPort, datos, sonido y se puede suministrar energía a las gafas de realidad virtual conectadas.
Y, por supuesto, no falta la referencia a NVLink, indicando el aumento sustancial de ancho de banda de comunicación entre dos tarjetas gráficas iguales. Si bien dos RTX 2080 Ti tendrán una comunicación agregada de 100 GB/s, el chip TU104 de la RTX 2080 solo dispone de un canal NVLink para una comunicación agregada de 50 GB/s. Aun así, es sustancialmente superior al ancho de banda que tenía Pascal con SLI HB, y muy superior a la que tiene SLI.

Entrando finalmente en el terreno del trazado de rayos, y que hay un núcleo específico para la generación de este tipo de información en cada SM. Como ha comentado Nvidia anteriormente, la arquitectura Turing está hecha para combinar la rasterización con el trazado de rayos. Para ello los sombreadores y los núcleos tensoriales funcionan en tándem para generar una versión preliminar de los gráficos —se generan triángulos que componen objetos—, pasarlos a los núcleos RT para evaluar intersecciones, y en función de ello generar los cambios en el sombreado o color de cada píxel a nivel individual.
Al hacer esto por hardware en vez de por software como se haría en la arquitectura Pascal y previas, de procesar una GTX 1080 Ti 1.1 gigarrayos por segundo a generar más de 10 GR/s en la RTX 2080 Ti.
La generación de un fotograma hace funcionar en conjunto todos los elementos de cada SM, si bien la mayor parte del peso se la lleva el sombreado usando los núcleos FP32, una parte la intersección usando los núcleos de trazado de rayos, y otra el procesamiento de redes neuronales para el DLSS. Un parte menor se la lleva las operaciones los núcleos de INT32.
En el libro blanco de Turing, Nvidia también ha añadido información sobre los chips TU104 y TU106 que conforman la RTX 2080 y RTX 2070 respectivamente. El chip TU104 está compuesto por 6 GPC, 23 TPC, 46 SM, y 2944 núcleos CUDA en total, con 368 núcleos tensoriales y 46 núcleos de trazado de rayos, fabricado con el mismo proceso de 12 nm FFN y con un tamaño de 545 mm2 frente a los 314 mm2 del GP104 a 16 nm. Es por tanto notablemente más grande, y de ahí que el precio de estas tarjetas gráficas no sea menor sino mayor. A mayor tamaño de la unidad de procesamiento gráfico (GPU), menos se producen por oblea, y por tanto el coste de producción por chip es mayor.
El chip TU106 está compuesto por 3 GPC, 18 TPC, 36 SM, y 2304 núcleos CUDA en total, con 288 núcleos tensoriales y 36 núcleos de trazado de rayos, fabricado con el mismo proceso de 12 nm FFN y con un tamaño de 445 mm2 frente a los 314 mm2 del GP104. Este es el chip en el que probablemente se base una hipotética «RTX 2060».
Fuente: Libro blanco de Turing. Vía: Guru3D, TechPowerUp, The Tech Report.



